スペシャルレポート 金融市場で使われている人工知能
金融市場で使われる人工知能
人工知能を用いた技術は金融市場でも使われています。後で述べるように人工知能には得意なこと、苦手なことがあり、金融市場で得意なことは他の分野に比べ多くないのですが、それでも人工知能が使用されている事例もあります。今回は、それらの事例を紹介しますが、その前にまず、なぜブームが終焉した今このレポートを書くのか、ブームの時期と技術が飛躍的進歩したり普及が進んだりする時期が無関係であること、そして、そもそも人工知能とよばれているものがどういうものなのかを説明します。
このレポートでは人工知能の仕組みの説明を長めにし、応用分野の説明はごく簡単なものにしました。というのも、仕組みが分からないとなぜそこで使えるのか分からない一方で、仕組みが分かればどこで使えるか自分で判断できるようになるからです。この方針でこのレポートは書かれていますのでご了承ください。
ブーム時の誤解
プロフィールに書いてある通り、私は2016年度から人工知能学会 金融情報学研究会*1の幹事をしております(現在は主幹事)が、この研究会が発足した2008年から研究発表をさせていただいています。この研究会は人工知能学会に属する研究会のうち、金融を専門に取り扱う唯一の研究会で、おそらく、人工知能の金融分野への応用を専門にかつ学術的に議論する、国内では唯一の場所ではないかと思います。発足当初の2008年ごろは、人工知能は一般社会からは見向きもされない、いわいる"冬の時代"でしたが、幹事になった2016年はちょうど一般社会での人工知能ブームが始まったころでした。このブームは2018年ごろまで、おおよそ3年くらい続いたのではないかと思います。調査会社のGarthnerによると人工知能は現在、"幻滅期"にあるとのことです*2。
このブームのころは私も日本銀行など*3、いろいろなところでお話しをさせていただきましたが、今では人工知能そのものの話をするのは京都大学にてゲストで講義をする時ぐらいになりました*4。ブームのころは人工知能に対する誤解も社会一般に広がってしまっていて、例えば、あらゆる分野で人間の頭脳を超える人工知能がもうすぐ現れるとか、大量の失業者が現れるとか、極端なものでは人類が滅亡するとか*5、それを打ち消すための話が講演時間の多くを占めることもありました。残念なことに、ブームが来る前にはそれについて語ったことがなかったのにブームが来るとその分野にとても詳しいかのように雄弁に語り、ブームが去るとまた語らなくなる人たちが少なからずいるのですが、そのような人たちが多くの誤解を一般社会にばらまいていきました。
なので、ブームの時にこういうレポートを書くと、このような本来なら無視してもよいような誤解を否定することに文面を割かなければならず、文章量の割には情報が少ないレポートにならざるを得ません。また、ブームが終わった後に読み返すと「なんでこんなくだらない説を否定することに文面を割いているのだろうか」と感じ、構成を理解するのに時代背景の知識が必要になってしまう可能性があったのです。今なら、このようなことはそこまで触れる必要がありません。そのため、ブーム終焉した今、このレポートを書くことにしたのです*6。
なぜこの時期にブームが来たのか謎:技術の進歩や普及とは無関係
これはどのようなブームでもそうなのですが、ブームが来た時期と、技術が飛躍的に発展したり技術の使用が普及したりする時期に関係があまりないです*7。特に一般社会でのブームの時期と、本当にその技術が普及していく時期は、あまり関係ないです。専門的に研究・開発している人たちの間では、"なぜ今ブームなんだろうか"という疑問すらでていました。一般社会でのブームが終わっても、実際の技術の進歩や普及の速さにはほとんど影響を与えていません。
むしろ、ブームが去ったことは、一般社会で当たり前のように使われ始めたことの裏返しでもあります。いちいち人工知能であると言う必要がなくなったのです。例えば、画像処理のアプリの広告で風景写真に写りこんだ人を消すような機能を宣伝するさい、いちいち"人工知能を使った"と枕言葉を付けなくなりました。株式市場では、2000年代初頭のITバブルのことをインターネットバブルとよんだりしますが、崩壊後の方がより多くの人がインターネットを使い、インターネットのない世界が考えられない時代になったことと似ていると思います。人工知能の普及はむしろこれからでしょう。
そもそも人工知能とよばれているものはどういうものなのか?
そもそも人工知能とはどのようなものでしょうか?どのような領域に人工知能が使えるのかは、その仕組みが分かれば見当がつきます。単にどこで使われているか列挙したものを聞くと、列挙されなかったところで使えるかどうか分かりませんが、仕組みが分かればどこで使えるかが自ら判断できるようになりますし、人工知能ではまったくできないことを提案したりすることを防ぐことができます。
人工知能学会のホームページに"人工知能研究"を説明したページがあります*8。そこには「人工知能(AI)とは知能のある機械のことです。しかし、実際のAIの研究ではこのような機械を作る研究は行われていません。AIは、本当に知能のある機械である強いAIと、知能があるようにも見える機械、つまり、人間の知的な活動の一部と同じようなことをする弱いAIとがあります。AI研究のほとんどはこの弱いAIです。」と書かれていて、研究分野の例として、遺伝的アルゴリズム、エキスパートシステム、音声・画像認識、機械学習、自然言語処理、情報検索など、コンピュータでデータを処理する技術が列挙されています。
一般社会ではこれらのコンピュータによるデータ処理技術が"人工知能"とよばれているのが現状です。上記の定義に従うなら正確には"弱い人工知能技術"とよばないといけないところですが、このレポートでも単に"人工知能"とよぶことにします。人工知能とは非常に広く意味を持つ言葉であり、とてもあいまいな言葉でもあります。あえて、あいまいにすることによって、研究領域を限定することなく柔軟な発想で多くのアイデアが生まれてきた研究分野であるとも言えるでしょう。ただその反面、その強すぎる言葉のイメージによって、時々、過剰な期待と失望を招いた分野でもあります。
誤解を恐れずにものすごく簡単に言えば、人工知能とは、コンピュータによる新しいデータ処理手法全般のことです。そのため、以前は人工知能とよばれていたものも普及してくると、いちいち人工知能とはよばれなくなります。先に列挙された情報検索は、いまでは単に"検索"とよばれるもので、インターネットでなにか調べる時にキーワードで検索するときに使われる技術のことです。25年くらいまでは"ロボット検索"とわざわざ"ロボット"を付けていた時代*9もありますが、今では、たとえ以前は人工知能とよばれた技術を用いていたとしても、単に検索としかよばなくなったのです。
人工知能の仕組み
まず初めに言っておきたいのが、人工知能とは言いますが、データ処理の方法は人間とは全く異なります。アプローチが人間とは全く違うのです。しかも技術の発展とともに近づいている訳でもなく、むしろ遠ざかっているものすらあります。例えば、自動翻訳技術では、文法や単語の種類などはあえて無視して単純に数値化してから処理する技術が現在では主流で、それまでの文法などを考慮した技術よりも飛躍的に翻訳精度が向上しました*10。そのため、人工知能が得意なこと、苦手なことは人間とは全く異なります。人間には簡単でも人工知能には全くできないことは多くある、というよりほとんどがそうだと思った方が良いでしょう。逆に、人間にとっては難しいことが人工知能はいとも簡単にやってのける分野がいくつかあります。そういう分野がどこなのかを理解するうえで、仕組みの理解が大事なのです。
2016年に、囲碁のトップ棋士が人工知能に敗れるニュースが一般の方々に衝撃を与えました*11。ここでは、囲碁を例に具体的に人工知能の仕組みを見ていきましょう。ここでは誤解を恐れず分かりやすさを重視して説明しますので、厳密には間違った部分もあるかと思いますがご了承下さい。
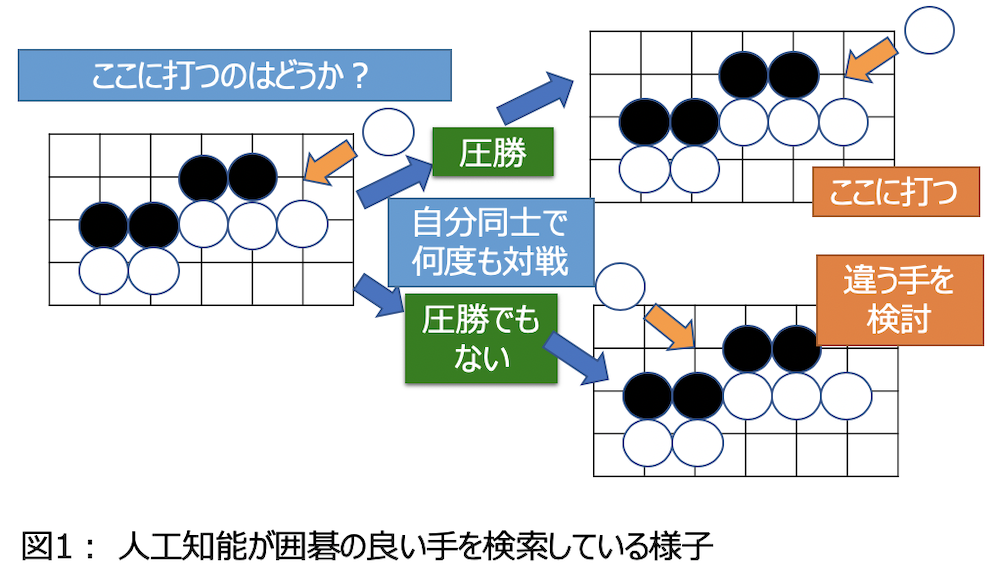
今、図1のような局面だったとしましょう*12。ここで白が図のような場所に置くかどうかを検討しているとします。人間の場合ですと、定石や全体の状況、先を読んだりして考えることになります。しかし人工知能の場合は、とりあえずそこに置いたとして、その後の展開を自分同士の戦いをおびただしい回数やってみて、勝率を計算します。もし圧勝するようだったらそこに置き、圧勝でもなければ違う場所も検討します。これを凄い回数を繰り返せば、今後の展開としてあり得る局面の多くを網羅でき、そこに置いたときの勝率が計算されるのです。
自分自身との戦いでは初めから人工知能は強い必要はありません。初めは適当に置くだけでもよく、勝ちやすい場所に置く確率が少しずつ高くなればそれで良いのです。この作業は膨大ですが、実は、囲碁の知識は必要ありません。囲碁が分からない私でも5000年くらいあれば、プロも驚愕の1手を見つけ出すことができるでしょう。このように単純だけれどもおびただしい回数を繰り返す必要があるものが、人工知能が得意なことなのです。そして、一般的に人工知能は大量のデータを必要としますが、この囲碁のケースのように自分同士の対戦で対局データを生み出せる場合もあります。
ニューラルネットワークの仕組み
もう少し詳しめの説明を試みてみます。機械学習の1つの手法であるニューラルネットワークの仕組みを、誤解を恐れずにごく簡単に説明します。ブームの時に一般社会でも知られることになったディープラーニング(深層学習)は、多数のニューラルネットワークをうまくつなぎ合わせ、調整の仕方を画期的な方法で工夫したものです。
図2をご覧ください。この図や以下の説明はSteven Millerさんのサイト*13を簡潔にしたものなので詳細はそれをご覧ください。一番左の列は入力データで囲碁の石の場所を示しているとしましょう。囲碁の碁盤は19×19=361なので、この列に361個の0または1のデータがあれば、碁盤に石があるかないかを表現できます。囲碁の石には白と黒があるので361×2=722個の0または1があれば盤面が完全に表現できますね。
さて左上に1のデータが入力されていますが、これに重み0.8を掛けて2番目の列の1番上の隠れ層に進みます。その下の入力データも1で、重みは0.2なので、これをかけて隠れ層に進みます。これらを足したものは1×0.8+1×0.2=1なのですが、この数字をシグモイド関数というものを用いて加工する作業を行い、0.73となります。入力層は本来なら722個あるハズなので、722個の入力データと重みを掛け合わせて足して、ようやく隠れ層の1番上の数値が出てきます。隠れ層が仮に100個あったとするとこの作業を100回繰り返してようやく隠れ層がそろうわけです。一番右の列は出力層ですが1つだけとします。100個の隠れ層の結果を同じように重みを付けて足し合わせて集計し丸めます。これが出力値です。
この出力値の答え合わせをします。答えとは、入力した碁盤の状況でその後白が勝っていれば1、負けていれば0とします。この答えは実際の対局結果でなくても、人工知能の自分同士の戦いの結果でも良いです。今回の答えは0、出力値は0.77なので、出力値を減らすと答えに近づきます。
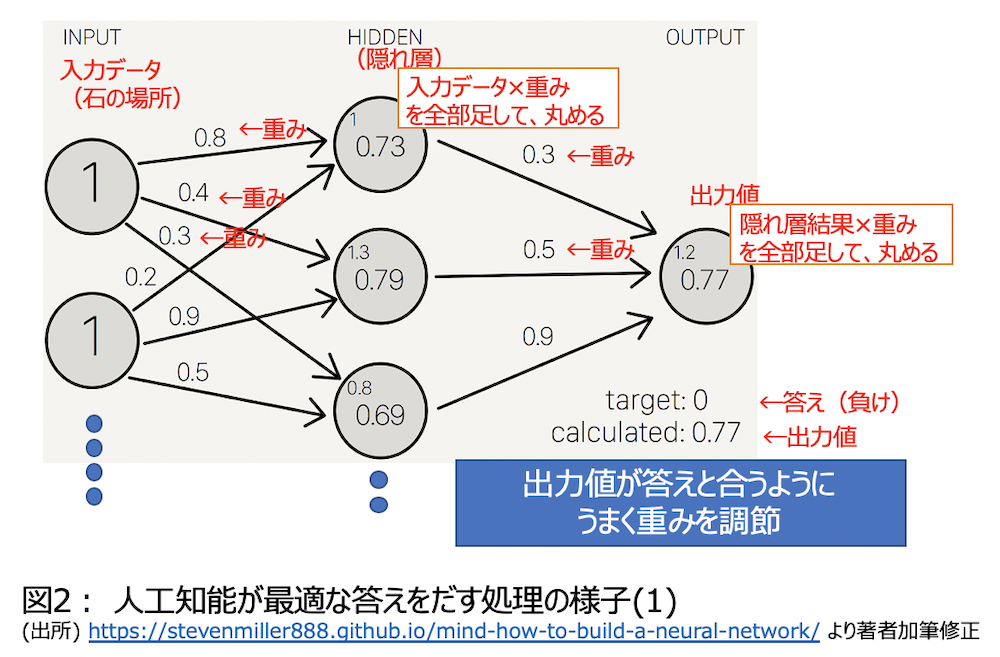
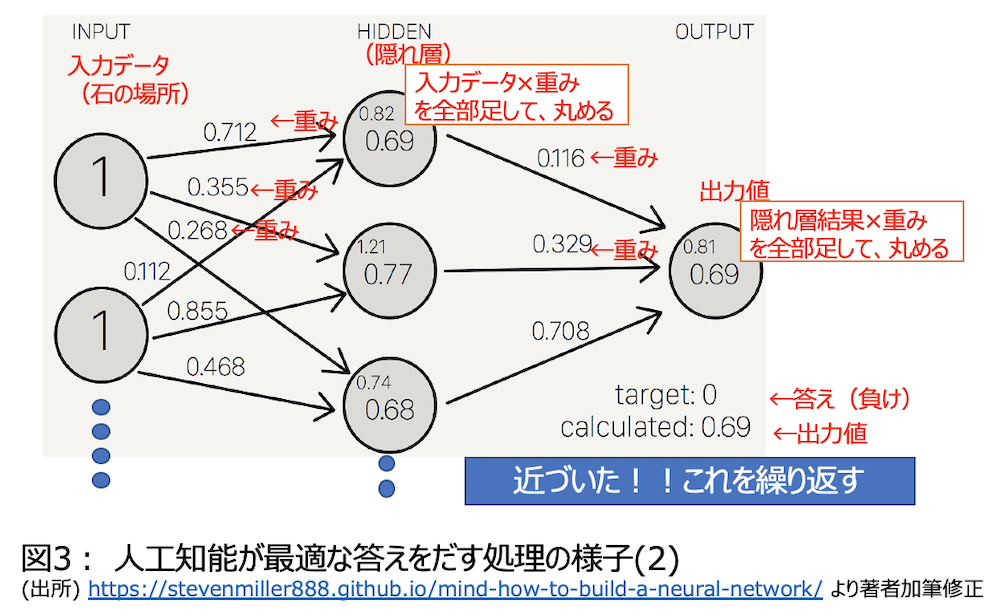
図3をご覧ください。出力値が小さくなるように重みを調整します。ここで完全に0になるように調整するのではなく、少し小さくなるように調整することに注意してください。というのも、先ほど白が負けたというデータは絶対ではなく、そういうケースもあったというだけだからです。同じ局面でも勝つことがあるわけで、このような対局データがたくさん集まって少しずつ正しい方向に調整されていくのです。
この調整のことを"学習"とよびます。そのためニューラルネットワークは機械学習の1つと言われるのです。学習と聞くと主体的に何か知識や経験を獲得していくイメージがあると思います。しかし、人工知能の分野で学習といえば、このような答えに近づく数値の調整のことです。人間の学習と人工知能の学習とではやっていることがまるで違うのです。また、人工知能での学習では多くのデータが必要です。人間は1つの経験から関連することを思考したうえで学習できるのですが、人工知能ではそれはできないのです。
人工知能が得意なこと苦手なこと
ここまで見てきた人工知能の仕組みから、得意なこと苦手なことが分かります。人工知能が囲碁を得意としているのは、ルールや盤の大きさがあらかじめ決まっていて、繰り返し同じことが起き、何度も試せるからです。囲碁の打ち手は、頭が悪くても、おびただしい回数繰り返せば、多くのケースを網羅できます。囲碁はものすごく細分化すれば簡単な作業に落とし込めます。もし、時間とともにルールや盤の大きさが変わったり、そこまでいかなくても、繰り返し同じことが起きなったりする性質があれば、何度も試せなくなりますから、おびただしい回数繰り返して多くのケースを網羅することはできなくなるのです。
人工知能は人間より本質的に頭がよくなったわけではなく、過去データのパターン分類や分析をします。新しいものを創造しているわけではありません。逆に言えば、人間は対局経験数のわりに異様に強いと言えます。人間ならば少ない経験からも思考を通じて学習できますが、人工知能にはできません。またデータがないところから何かを作るといった創造的なことも人工知能にはできず、囲碁というゲームを作り出したりはできませんし、囲碁が楽しいかどうかも分かりません。人工知能は、人間にとって有用な道具なのです。
まとめると、人工知能は、人間より頭は悪いが、飽きずに、大量に、速く、データを処理できます。1人で繰り返し練習できる、取り扱う範囲があらかじめ限定されている、繰り返し同じことが起きる安定性があるような問題が得意です。
文章の"処理"もできる
ここでは、文章の処理を人工知能がどうのように行うのかを紹介します。ここまで人工知能の仕組みの説明を見て、「数字のデータしか扱えないのでは?文章が扱えるのか?」と思われる方も多いでしょう。しかし、囲碁の盤面を数値に変えたように、文章も数値に変換して処理すれば、文章の"処理"もできるようになるのです。ここで文章の"処理"であることを強調しておきます。決して"意味"を理解しているわけではありません。しかし、意味が分かっていなくてもおびただしい回数の単純処理の積み上げで、いろいろな有用な処理ができることをお示ししたいと思います。
人工知能が文章をどのように処理しているか、川添愛先生の書籍"ヒトの言葉 機械の言葉"*14と"働きたくないイタチと言葉がわかるロボット"*15が非常に分かりやすく書いています。人工知能が得意とする文章処理には、話題の範囲を限定した音声認識、目的のないおしゃべり、異様にマニアックな質問に答える、動画に出てくるものが何であるか表示する、前提知識や状況把握が必要ない論理式に落とし込める文章の正誤判定などです。
人工知能が苦手なのは常識的な状況の把握や発言者の意図を読み取ることです。そのため、人間にとっては読みにくい、厳密に書かれた文章や専門用語辞典を引かないと分からない専門的で厳密な話、逆に正解不正解が全くないおしゃべりなどが処理しやすいものとなります。ここでは、異様にマニアックな質問に答えるという処理をどのように行っているのか見てみましょう。
異様にマニアックな質問に答えるという処理
例えば「1603年に江戸幕府を開いたのは誰?」という質問を考えましょう。人間の場合だと「江戸時代の始まりだからその前の戦国時代を勝ち抜いた人だったな」とか考えるでしょう。または、大河ドラマなどでみたシーンを思い出して答える人もいるかもしれませんし、丸暗記している人も多いと思います。しかし人工知能の方法は全く異なります。
まず、何を聞かれているのかを判断します。ここでは「誰?」と聞かれているので人物が聞かれていることが分かります。ここまででも多くの技術があるのですがここでは省略します。次に検索をします。検索キーワードは「1603年」と「江戸幕府」です。ここで、「1603年」が何時代であるとか「江戸幕府」が政治形態を指しているとか、そういうことは考慮しません。とにかくこれらのキーワードで検索します。インターネット上で普通に検索しているイメージで良いです。すると、非常に多くのページが候補として出てきます。例えば、「江戸幕府は、江戸城を本拠地におく徳川氏による武家政権です。1603年に征夷大将軍に任命された徳川家康が江戸に開き、第15代の徳川慶喜が大政奉還をするまでの間、265年間にわたり日本国の政治を行いました」といった文章がでてきます*16。人間ならこの1つの文章だけで「『徳川家康が開き』と答えがそのまま書いてある」と分かるわけですが、人工知能は文章の意味は理解できず、人間のように答えが書いてあると判断できない(そもそも問題の意味も分かってない)ので、この文章だけでは答えが分かりません。これらのキーワードが含まれる大量のページを統計的に処理して答えを導き出すのです。
これらの大量のページには当然「1603年」と「江戸幕府」が含まれている訳ですが、これらのキーワードに近い位置に配置された人物を抽出します。上記の例でもそうでしたが「徳川家康」や「徳川慶喜」などが、これらのキーワードの近くに多く存在することが分かりますが、最も高い確率で出てくる人物、最も頻繁に最も近くに配置されていた人物などのランキングを作り、それらを総合して「徳川家康」を導き出します。「徳川慶喜」よりも「徳川家康」の方が近くにかつ高頻度で一緒にでてくることから判断するのです。
答えが書いてある一般的な文章が苦手
そのため、文章にすでに答えが書いてある一般的な文章で、インターネットを検索しても出てこない質問は、人工知能は苦手です。例えば、「フク子さんは居間で新聞を手に取り台所を通って、仕事部屋に行きました。新聞は今どこにあるでしょう?」という文章を考えましょう(この例は先にあげた書籍*15にでてきます)。人間ならすぐに答えは「仕事部屋」であることが分かるわけです。しかし人工知能は文章の意味が分からないので答えが分かりません。先に説明した手順と同じように考えます。
まず、聞かれているのは場所であることが分かります。次に、「仕事部屋」や「居間」、「新聞」などをキーワードとして検索します。すると物件紹介などのページが多数かかります。これらのページを見ても答えが分からないのは当然でしょう。これらのキーワードの近くに「仕事部屋」が他と比べて多く出現するとは考えにくいです。当たり前ですが、「ある人物が新聞を手に取って台所を通り仕事部屋に言った場合、新聞は仕事部屋にある」などと当たり前のことを説明したページが多数存在することはあり得ません。そんな当たり前のことをわざわざ説明しないからです。それが先ほどの「徳川家康」の場合とは異なるのです。「徳川家康が江戸幕府を開いた」と説明したページはたくさんありため、人工知能にとっては簡単に答えを導き出せます。一方この「フク子さん」の問題は、人工知能にとってはとても難しい問題なのです。
常識的な状況の把握や発言者の意図の読み取りができない
人間にとって簡単でも人工知能にとって極めて難しいのが、常識的な状況の把握や発言者の意図の読み取りです。こちらも先にあげた書籍*15にでてくる例ですが、「洗濯物を干して」と言われた場合、人間ならそこにある洗濯物をすべて干そうとします。一つか二つだけ干して残りを放ったりはしない訳です。しかし人工知能は、何枚干せばよいのか分からないのです。
一方、「台所から取り皿を持ってきて」と言われた場合、人間なら必要な枚数だけ持ってきます。台所にある取り皿をすべて持ってきたりはしません。しかし人工知能は何枚持ってくればいいかわからないのです。人間はその作業の意味が分かっているため少しくらいあいまいな部分があっても補うことができます。一方、人工知能はそれが分かっていないため、少しのあいまいさも補えないのです。なので、人工知能は法律や特許情報などの非常に厳密に書かれた文章の方が得意なのです。
金融市場で使われる人工知能:投資家の補助となるツールや周辺領域での活躍
さてここからは、金融市場で使われている人工知能について書きます。金融市場の人工知能と聞くと、人工知能が自動で売買しているイメージがあるかもしれません。もちろん、そういうのもあるのですが、人工知能の活躍はむしろ投資家の補助となるツールや周辺領域に多く見られます。ここまで長い前置きのおかげで、なぜそれが、人工知能の得意な分野なのか分かると思います。むしろ、ここからの説明がなくても活躍できる領域が分かった方も多いのではないかと思います。
金融市場は一見データが多いように思えるものの、時代によって取引参加者の行動や取引制度、時代背景などが異なり、囲碁のように正確に繰り返し同じことが起こるわけではありません。以前のレポートで述べたように繰り返し同じことが起きる斉一性が疑われているくらいです*17。ましてや、自分同士の戦いで新たにデータを生むこともできません。そういった意味では金融市場は人工知能が苦手とする分野ですが、周辺領域まで含めれば活躍の場は多くあります。
長い前置きのおかげでここから先、仕組みの説明はほぼ省略できますので、簡潔に述べていきます。私は人工知能の金融市場での活躍分野を"文章の処理"、"アルゴリズム取引"、"不公正取引の取締り"、"制度設計"と大きく4つに分けて整理しています。"制度設計"は私の専門で、人工市場を用いた規制やルールの議論です。これについては次回以降の別のレポートで述べたいと思います。
文章の処理
金融市場には多くの文章があります。実は私が幹事をしている人工知能学会 金融情報学研究会*1での研究発表で一番多いのは、文章の処理に関する研究です。金融市場にはとても読み切れないほどの文章があり、それをうまく処理することは需要が高い技術のようです。
例えば、決算単信の重要部分の抜き出しや要約*18があります。企業の事業内容を示す文章と、業績を示すときによく使われる単語をあらかじめまとめておき、決算単信がでるとそれらと比較してよく当てはまる部分を、重要な個所として抜き取れば、業績にとって重要な部分を抽出できます。それらをうまく組み合わせれば決算単信の要約となるのです。業績を表す文章は各社安定していて、会社間での違いも大きくないことから人工知能の得意分野です。最近では統合報告書やESGに関連する文章などの処理も求められているようです*19。
また、要約ができるということは、何か元の文章があれば、そこから文章を作り出すことができるということになります。企業が決算を発表した直後のニュース記事などはすでに決算単信の文章などを元に人工知能で書かれている場合があります*20。もともとこのような第一報は決算単信のコピー&ペーストを元に作られており、人工知能はこのような「うまくコピー&ペーストを行う」ことが得意なのです。後で述べるように、アルゴリズム取引のうち、生成されたばかりの文章を読み込ませて売買を判断させることもあります。なので、人工知能が文章を書き、その文章を人工知能が読み込んで売買するという世界はすでに来ています。
その他には銘柄の分類があります。文章から銘柄間でどれくらい似ているかを判断し、例えば、業種分類を作ったり*21、投資テーマを自動生成して関連銘柄をリスト化したりしているようです。
金融からは外れてしまいますが、スポーツの結果を報じる第一報などでは人工知能が書いた記事が大手紙でも使われているようです*22。また、契約書などの法律関係の文章のチェックするツールなどもあります*23。外国語の自動翻訳も最近精度が上がってきました。実は、以前は文法を分析するなど人間と同じような手法をなるべく取ろうとする方法が主流でしたが、2017年ごろにそういうのは完全に無視して、すべて数値化してから、統計的な類似性だけで翻訳する手法が登場し、飛躍的に精度があがりました*10。人間の方法から離れたほうが、性能が上がることは時々あり、その好例と言えるでしょう。
アルゴリズム取引
アルゴリズム取引に関しては以前のレポート*24でも紹介しましたが、この領域では人工知能が使われることがあります。大きな株数を注文するとき、市場に大きな影響を与えないよう少しずつ注文を小分けにして出すわけですが、それを自動的に機械で行うのが執行アルゴリズムです。執行アルゴリズムでは、板の状況から数分以内といった短期的に上がりやすいか下がりやすいかを人工知能が判断し、買いを急いだり遅くしたりしているようです*25。数分以内の株価動向は、企業活動や経済状況とはほとんど関係なく、板の状況だけで決まることが多いうえ、その板の状況も繰り返し似たようなパターンが見られるため、人工知能が得意とする分野です。
人工知能だけで銘柄選び、売買の自動化まですることは多くないようですが、ファクターへの投資においては使われている場合があるようです。ファクターへの投資とは、例えば、PBR(時価総額/自己資本)が低い銘柄を多数買うといった、ある定量的な指標にもとづいて多くの銘柄を保有する手法で、ほとんどの場合、多数のファクターを合成しています。一般にクオンツとよばれる運用の多くはこれです。新しいファクターの作成や、ファクターを混ぜる重みづけを時間とともに変化させるときなどに人工知能が使われているようです*26。
また、以前のレポート*24でも紹介しましたが、日本銀行の金融決定会合の結果をお知らせする文章を自動的に解析して瞬時に取引を行う人工知能もかつてはありました*27。
不公正取引の取締り
金融分野に限らず、監視カメラの画像の分析など、犯罪の取締りで人工知能は大活躍しています。犯人の写真と防犯カメラに写っている人が同じ人かどうか、つまり顔が類似しているかどうかを判定したり、非常にありがちな不審な動きを検知したりするなどは、人工知能が得意とする分野です。この取締りという分野は人工知能の普及でもっとも恩恵を受ける分野の1つであることは間違いありませんし、悪用が最も懸念される分野でもあります*28。
人工知能を用いた不公正取引の取締りは以前のレポート*24でも紹介しました。例えば、相場操縦を意図したインターネット上の書き込みを見つける技術があります。過去の相場操縦を意図した書き込みと似ている特徴を持つ書き込みを広大なインターネット空間から探してくるのです。このような大量のデータを処理するのは人工知能が得意とするところで、書き込みにも典型的な特徴があるため活躍できる領域です。金融庁ではすでにこのような技術を使って取締りの補佐に使っているようです*29。東京証券取引所でも膨大な板のデータの中から、過去の不公正取引と似た特徴をもつ取引を見つける人工知能が使われています*30。
一方で、人工知能が行う不公正取引も懸念されています。それについては以前のレポート*31で詳しく取り上げましたが、人工知能は、その作成者および使用者が全く意図していなくても、相場操縦という取引戦略を発見できる可能性を示した研究があります*32。しかし現在の規制ですと、この作成者や使用者の責任を問えない可能性があり、このことを悪用して「人工知能が勝手にやった」と言い逃れするものがでてくるかもしれません。法改正の議論が必要とされています。
金融市場で使われる人工知能:便利な道具として活躍
人工知能は人間とは、得意なこと苦手なことが全く異なります。人間が得意なことは人間が行い、人工知能が得意なことは人工知能を使って処理する、つまり、便利な道具として人間が使うものです。人工知能そのものに善か悪かはありません。ハサミと同じように、良い使われ方をするか悪い使われ方をするかは使う人間次第なのです。人工知能のブームは終焉しましたが、普及はまだまだこれからです。これからどのように応用分野が広がっていくのか、注目していきましょう。
(*1) 人工知能学会 金融情報学研究会ホームページ
(*2) Gartner、"ガートナー、「日本における未来志向型インフラ・テクノロジのハイプ・サイクル:2020年」を発表"、2020年
https://www.gartner.co.jp/ja/newsroom/press-releases/pr-20200910
(*3) 水田孝信、 "ショートプレゼンテーション:市場におけるAIの活用と今後の可能性"、 日本銀行決済機構局・金融市場局合同コンファレンス「AIと金融サービス・金融市場」、 第2部:パネルディスカッション「AIと金融市場へのインパクト」、 日本銀行、 2017年4月13日
https://www.boj.or.jp/paym/forum/rel170412c.htm
(*4) 以下に講義資料がおいてあります。
https://mizutatakanobu.com/20210118.pdf
(*5) このような誤解の広がりは欧米の方が日本よりひどかったようです。例えば、以下の書籍では、多くの(人工知能が専門でない)著名人が人工知能によって人類が滅亡させられると主張していたと書いてあります。
Jean-gabriel Ganascia, "Le mythe de la singularite", Le Seuil, 2017
(邦訳:伊藤直子監訳、小林重裕訳、"そろそろ、人工知能の真実を話そう"、早川書房、2017年)
https://www.hayakawa-online.co.jp/shopdetail/000000013576/
(*6) もちろん、専門家が誤解を解く活動は重要です。人工知能学会の学会誌では2017年にブームに関して特集が組まれ、下記のその特集の説明において、研究者が誤解を解く活動をすることが重要であると指摘しています。人工知能の場合、今回のブームは3回目で、1980年代の前回のブーム終焉時に招いた大きな失望を回避するためにも、誤解を解くことが重要だと実感している研究者が多かったのでしょう。
鳥海不二夫、"小特集「マスメディアから見た人工知能」にあたって」"、人工知能学会誌、2017年11月号
https://www.jstage.jst.go.jp/article/jjsai/32/6/32_927/_article/-char/ja/
ちなみに、3回のブームで人工知能に寄せられた一般社会からの過剰な期待は同じようなものだったことが知られています。1950-60年代の1回目のブームの時にも「ロボットに多くの職が奪われる」や「自動車は完全な自動運転になる」などの新聞記事が見られました。
河島茂生、"資料1 河島 構成員 御発表資料"、総務省AIネットワーク社会推進会議分科会、2017年11月9日
https://www.soumu.go.jp/main_sosiki/kenkyu/ai_network/02iicp01_04000117.html
(*7) もちろん全く関係ないわけではないです。データが多く集められるようになった、そのとき人工知能が挑戦していることが一般の人にとってすごいことに思えた事例、例えば囲碁のトッププロ棋士が人工知能に負けたなどがあったことが挙げられます。囲碁や将棋の研究がひと段落した今、人工知能にとってはさらに難しい「テレビゲームをクリアする」という研究が盛んになりましたが、一般の人からすると、トップ棋士に勝利することより簡単に感じられ盛り上がりにかけることは否めません。例えば、以下のような研究があります。
Tim Salimans, Jonathan Ho, Xi Chen, Szymon Sidor, Ilya Sutskever, "Evolution Strategies as a Scalable Alternative to Reinforcement Learning", arXiv, 2017
https://arxiv.org/abs/1703.03864
(*8) 人工知能学会ホームページ、"人工知能研究"
https://www.ai-gakkai.or.jp/whatsai/AIresearch.html
(*9) "ロボット検索"ではない検索として、手作業で各ホームページをカテゴリーに分類し、それを用いて検索す る"カテゴリー検索"があります。
(*10) 須藤克仁、 "ニューラル機械翻訳の進展 -系列変換モデルの進化とその応用-"、 人工知能学会誌、 2019年7月号
https://doi.org/10.11517/jjsai.34.4_437
(*11) "圧勝「囲碁AI」が露呈した人工知能の弱点"、日本経済新聞、2016年3月17日
https://www.nikkei.com/article/DGXMZO98496540W6A310C1000000
(*12) 著者は囲碁が分からないので現実的な局面かどうかは分かりません。
(*13) Steven Miller, "Mind: How to Build a Neural Network (Part One)", 2015
https://stevenmiller888.github.io/mind-how-to-build-a-neural-network/
(*14) 川添愛、"ヒトの言葉 機械の言葉"、角川新書、2020年
https://www.kadokawa.co.jp/product/321909000011/
(*15) 川添愛、"働きたくないイタチと言葉がわかるロボット 人工知能から考える「人と言葉」"、朝日出版社、2017年
https://www.asahipress.com/bookdetail_digital/9784255010038/
(*16)
https://nihonshimuseum.com/edo-bakufu/
(*17) 水田孝信、"市場は効率的なのか?検証できない仮説の検証に費やした50年"、 スパークス・アセット・マネジメント スペシャルレポート、 2020年12月22日
https://www.sparx.co.jp/report/detail/501.html
(*18) 酒井浩之、 西沢裕子、 松並祥吾、 坂地泰紀、"企業の決算短信PDFからの業績要因の抽出"、 人工知能学会論文誌、 30巻1号 pp. 172-182、 2015 年
https://doi.org/10.1527/tjsai.30.172
(*19) 例えば、以下のような研究があります。
土橋諒太、 中田和秀、 "BERTを用いた有価証券報告書からのESG関連文抽出"、 第26回金融情報学研究会、2021年
前原義明、 久々宇篤志、 長部喜幸、 "特許ドメイン特化型BERTによる脱炭素関連特許技術の「見える化」"、第27回金融情報学研究会、2021年
(*20) 日本経済新聞社"決算サマリー"
https://www.nikkei.com/promotion/collaboration/qreports-ai/
(*21) 磯貝孝、"株価の動的相関の推定に関する実証分析"、日本銀行ワーキングペーパーシリーズ、2015年
https://www.boj.or.jp/research/wps_rev/wps_2015/wp15e07.htm/
(*22) "AIが高校野球の戦評記事を即時作成 朝日新聞社が開発"、朝日新聞、2018年8月15日
https://www.asahi.com/articles/ASL890GLKL88ULZU011.html
(*23) "契約書タイムバトル"という、限られた持ち時間で2人の対戦者が契約書の編集合戦をして自分に有利になるようリアルタイムで交渉する競技イベントで、2018年に人工知能体対人間の対戦がありました。
"AIは人間に勝てるのか!?LegalForceの挑戦"、2018年12月10日
https://www.wantedly.com/companies/legalforce/post_articles/147076
(*24) 水田孝信、"高頻度取引(3回シリーズ第3回):高頻度取引ではないアルゴリズム取引と不公正取引の取り締まり高度化"、 スパークス・アセット・マネジメント スペシャルレポート、 2019年6月13日
https://www.sparx.co.jp/report/detail/316.html
(*25) 例えば、以下で述べられています。
紺谷傑、 "ショートプレゼンテーション:トレーディングフロアーでのAI実務"、 日本銀行決済機構局・金融市場局合同コンファレンス「AIと金融サービス・金融市場」、 第2部:パネルディスカッション「AIと金融市場へのインパクト」、 日本銀行、 2017年4月13日
https://www.boj.or.jp/announcements/release_2017/rel170412c.htm/
"コアテクノロジー・人工知能&ビッグデータ活用/野村証券-深層学習で株価を予測"、 日刊工業新聞、 2016年5月30日
https://www.nikkan.co.jp/articles/view/00386896
(*26) 例えば、以下のような研究があります。
阿部真也、中川慧、"グローバル株式市場における深層学習を用いたマルチファクター運用の実証分析"、 第33回人工知能学会全国大会、2019年
https://doi.org/10.11517/pjsai.JSAI2019.0_4Rin135
(*27) 熊野雄介、 五島圭一、 "金融政策アナウンスメントとアルゴリズム取引:ウェブページへのアクセス情報を用いた検証"、 日本銀行金融研究所ディスカッションペーパーシリーズ、 2018-J-11、 2018年
https://www.imes.boj.or.jp/research/abstracts/japanese/18-J-11.html
(*28) 西垣通、河島茂生、"AI倫理 人工知能は「責任」をとれるのか"、中公新書ラクレ、2019年
https://www.chuko.co.jp/laclef/2019/09/150667.html
(*29) "株価操作狙うあおり投稿抽出、SNS監視強化 金融庁"、日本経済新聞、2019年6月5日
https://www.nikkei.com/article/DGXMZO45654000U9A600C1EE9000/
(*30) "売買審査業務への人工知能の導入について"、 日本取引所グループ、 2018年3月19日
https://www.jpx.co.jp/corporate/news/news-releases/0060/20180319-01.html
また、以下の資料も参考になります。
指田浩希、 "人工知能の売買審査業務への適用"、 第20回 人工知能学会 金融情報学研究会、 2018年
(*31) 水田孝信、"人工知能が不公正取引を行ったら誰の責任か?"、 スパークス・アセット・マネジメント スペシャルレポート、 2020年8月4日
https://www.sparx.co.jp/report/detail/499.html
(*32) 水田孝信、"人工知能は相場操縦という不正な取引を勝手に行うか? -遺伝的アルゴリズムが人工市場シミュレーションで学習する場合-"、 第34回人工知能学会全国大会論文集、 2020年
https://doi.org/10.11517/pjsai.JSAI2020.0_2L5GS1305
当レポートは執筆者の見解が含まれている場合があり、スパークス・アセット・マネジメント株式会社の見解と異なることがあります。
上記の企業名はあくまでもご参考であり、特定の有価証券等の取引を勧誘しているものではございません。


